I Wrote A Summarizer For HackerNews, Here’s What I Learned
I've been a fan of HackerNews for a while now, but I've been struggling to keep up with the latest news lately. It used to be a total time-suck for me, like Facebook's Reels or YouTube's shorts, where I could mindlessly click and consume content for hours. But after taking a break from HN for a few months, I realized catching up was way too overwhelming. There are just too many interesting links to click on and I can't consume content as fast as I used to. I guess I'm missing my youth and my long attention span.
I had an idea to build a version of HackerNews that fetches top stories, summarizes them, and presents them in bite-sized reads. So, I created HackRecap, a quick weekend project to make consuming HN stories easier for me. I had three goals in mind:
- Maintain the original spirit of HN by keeping navigation and story browsing experience mostly the same
- Provide the tl;dr of stories at a glance, while still allowing for easy access to the full article
- Create an easy-to-maintain and run platform
The result is something that mostly works, and it’s good enough to show me story summaries and get me interested in reading the full stories if I wanted to, but it still has a bunch of limitations:
- Pages that require Javascript aren’t fetched properly. I suppose I could run a headless browser, render the page, and fetch the text from that, but it’s an additional moving part that I’d like to do away with for now

- Pages that aren’t necessarily stories or articles, or which display dynamic content, don’t really work.

- Depending on the fetchable content from the main article body, the summary may be completely unrelated. In this example,
tl;drhas nothing to do withPrimateJS, buttl;dris the instruction I give DaVinci to summarize the content for me.
- In the summarizer script itself, there are still pages that fail to be fetched or can’t be parsed.
- Because of all the reasons above, the stories presented in HackRecap is just a subset of the actual top stories from HackerNews. So I’m probably missing out on a couple of stories every day.
Here’s how HackRecap works and what I learned while building it:
- First, I fetch the top stories from the HackerNews API. That’s pretty straightforward: the API first returns a set of story id’s, which I then iterate over to fetch the story detail.
- For every story fetched, I use Goose to fetch the article text and top image. This bit was surprisingly not as straightforward as I originally thought, since webpages aren’t really structured exactly the same way. As good as Goose is, it’s not perfect: for paywalled articles, and for pages with a lot of sidebar or footer text, the wrong text is fetched resulting in an incorrect summary down the line. Somewhere in there I think there’s a machine learning approach to identifying the proper text, maybe in conjunction with a headless browser, but I haven’t quite cracked it yet.
- I take the downloaded text and recursively chunk them by counting the tokens using OpenAI’s tiktoken. OpenAI’s text completion API has a token limit of 4096 tokens. Thankfully they provide a library called tiktoken which I use to encode the text into tokens which I can then use to chunk longer contents before sending them over to OpenAI’s API. This bit was what I spent most of my time figuring out. Initially, I naively tried to just send the entire text for summarization, but that ran into the 4096 token limit quickly and many times. My initial chunking approach was also naive, counting characters instead of tokens, which for the most part was ok but I wanted to maximize my limits a little better. It also took me a few iterations to do the recursive summarization and final cohesion summary just right.
- I recursively chunk and summarize the tokenized text via the API until I get a final summary that’s cohesive.
What was surprising to me was how easy this was. In fact, all I had to do was feed every chunk to OpenAI and tell it
tl;dr, take all the chunk summaries together, see if it’s short enough for one last “cohesion summary”, and thentl;drthat again. - Finally, I serve everything up on a simple Flask page. The default Python web app stack with Flask, SQLite, and Redis.
To see how all of that is done in detail, here’s the link to the Github repo: https://github.com/KixPanganiban/hackrecap Feel free to fork it, submit Pull Requests, or just give it a spin. You’ll need a working OpenAI API key to run the summarizer.
I saw this project as an opportunity to experiment with AI-assisted coding, and I don't think I'll ever go back. Having access to Github Copilot and ChatGPT feels like having a junior developer on hand who is well-read but needs some micromanaging. However, with enough direction and detail, I get amazing results at an astonishingly fast pace.
For example, when I wanted to automate the deployment of HackRecap to my go-to Linode VPS, I instinctively reached for Ansible, which was my go-to tool in the past. However, I had forgotten how to write playbooks for it. Instead of searching for information online and trying to relearn everything, I simply asked ChatGPT to "Write an Ansible playbook that connects to my remote server as root, pulls the latest main in this folder, restarts and rebuilds the docker containers via docker compose, and flushes the redis cache via docker compose exec to the redis container." The result was a playbook code example that was almost good enough to run, except for a few quirks. Even then, I just had to tell ChatGPT things like "Make the docker compose up step also pass an environment variable called OPENAI_KEY," and the playbook code was regenerated with the necessary changes.
What about the costs? Prototyping HackRecap, fine tuning the completion parameters, and resummarizing hundreds of articles over and over again isn’t cheap, but it isn’t prohibitively expensive either. Since I started the project, I’ve spent around $88 on OpenAI so far:
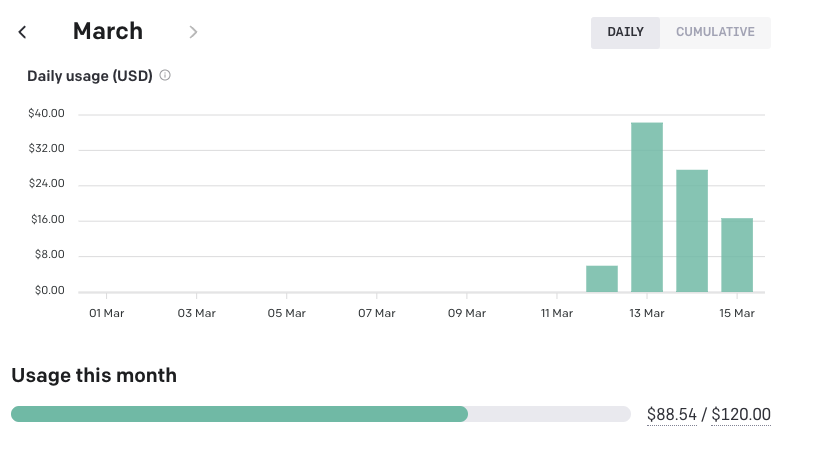
It’s not cheap, but it’s definitely cheaper than rolling out my own ML infrastructure, or heck, even learning how to write and run my own ML code.
Overall, this was a really enjoyable project to work on. I learned a lot about OpenAI's APIs, GPT, and AI-assisted coding. Most importantly, I discovered that almost anyone with internet access can now run powerful machine learning workloads without needing to have extensive coding skills. The future feels exciting!